
美中AI竞赛新视角:2025年Ollama部署对比与全球AI模型趋势洞察
Ollama 是一个流行的开源工具,旨在简化在本地运行、创建和共享大型语言模型(LLM)的过程。它将模型权重、配置和数据捆绑到一个由 Modelfile 定义的包中,并提供了一个与这些模型交互的API。这使得开发者和研究人员能够轻松地在个人计算机或服务器上部署和实验各种先进的 AI 模型。
1. 引言
Ollama 是一个流行的开源工具,旨在简化在本地运行、创建和共享大型语言模型(LLM)的过程。它将模型权重、配置和数据捆绑到一个由 Modelfile 定义的包中,并提供了一个与这些模型交互的API。这使得开发者和研究人员能够轻松地在个人计算机或服务器上部署和实验各种先进的 AI 模型。
本报告旨在通过分析全球范围内部署的174590个 Ollama 实例数据,揭示其部署趋势、模型偏好、地理分布及网络特征。
注: 第5章节及第7章节数据统计来源全部174590个实例数据,第6章节数据来源于可访问实例数据;因为一些安全原因,我们并未对Ollama的版本统计信息列出。
数据截止日期: 2025年04月24日。
报告来源: Tenthe AI https://tenthe.com
作者:Ryan
2. 执行摘要
本报告基于对全球公开 Ollama 实例的扫描和API探测数据分析得出。主要发现包括:
全球范围内,在初步通过Fofa识别的约174590条记录(99,412个独立IP)中,成功探测到 41,021 个可访问API的 Ollama 实例,分布在 24,038 个独立IP地址(可访问比例约 24.18%)。
从地理分布来看,美国和中国是 Ollama 部署数量最多的国家。云服务提供商,特别是 AWS、阿里云和腾讯云,是 Ollama 实例的主要宿主。
模型部署呈现多样性,
llama3、deepseek-r1、mistral和qwen系列模型广受欢迎。其中llama3:latest和deepseek-r1:latest是部署最广泛的两个模型标签。7B-8B 参数规模的模型是用户首选,同时,Q4_K_M 和 Q4_0 等4位量化模型因其在性能和资源消耗间的良好平衡而被广泛采用。
默认端口
11434是最常用的端口,且多数实例通过 HTTP 协议暴露服务。
3. 数据来源与方法论
本报告的数据主要来源于两个阶段:
初步扫描:通过Fofa等网络空间搜索引擎,使用
app="Ollama" && is_domain=false条件初步识别全球可能部署的 Ollama 实例。此阶段发现 174,590 条记录,去重后涉及 99,412 个不同IP。API验证与数据深化:对初步扫描到的IP地址进行
ip:端口号/api/tags的API接口探测,以确认Ollama服务的可访问性并获取其上部署的具体AI模型信息。此阶段共确认 41,021 个可成功响应的Ollama实例(来自 24,038 个独立IP,数据存储于ollama表中)。最终数据存储于
ollama表里面
本报告的分析主要基于 ollama 表中的数据,该表包含了API探测成功的记录及其详细信息,包括IP、端口、地理位置、响应的JSON(包含模型列表)等。
4. 总体部署统计
Fofa初步扫描记录数:174,590
Fofa初步扫描独立IP数:99,412
可成功访问
/api/tags的Ollama实例数:41,021 (来自ollama表status = 'success'的记录)对应的独立IP地址数:24,038 (来自
ollama表status = 'success'的记录)可访问 IP 占初步识别 IP 的比例:(24038 / 99412) * 100% ≈ 24.18%
这表明,在所有通过 Fofa 识别出的 Ollama 实例中,约有四分之一的实例可以被公开访问其 /api/tags 接口,并允许我们获取其部署的模型信息。
5. 地理分布分析
5.1 Top 20 部署国家/地区
下表展示了 Ollama 实例独立IP数排名前20的国家/地区。
排名 | 国家/地区 | 独立IP数 |
|---|---|---|
1 | 美国 | 29195 |
2 | 中国 | 16464 |
3 | 日本 | 5849 |
4 | 德国 | 5438 |
5 | 英国 | 4014 |
6 | 印度 | 3939 |
7 | 新加坡 | 3914 |
8 | 韩国 | 3773 |
9 | 爱尔兰 | 3636 |
10 | 法国 | 3599 |
11 | 澳大利亚 | 3558 |
12 | 巴西 | 2909 |
13 | 加拿大 | 2763 |
14 | 南非 | 2742 |
15 | 瑞典 | 2113 |
16 | 中国香港特别行政区 | 1277 |
17 | 以色列 | 675 |
18 | 中国台湾 | 513 |
19 | 俄罗斯 | 475 |
20 | 芬兰 | 308 |

5.2 全球 Top 20 城市部署
下表展示了全球范围内 Ollama 实例独立IP数排名前20的城市。
排名 | 城市 (City) | 国家/地区 (Country) | 独立IP数 |
|---|---|---|---|
1 | Ashburn | 美国 | 5808 |
2 | Portland | 美国 | 5130 |
3 | Singapore | 新加坡 | 3914 |
4 | Frankfurt am Main | 德国 | 3908 |
5 | Beijing | 中国 | 3906 |
6 | London | 英国 | 3685 |
7 | Columbus | 美国 | 3672 |
8 | Mumbai | 印度 | 3637 |
9 | Dublin | 爱尔兰 | 3631 |
10 | Tokyo | 日本 | 3620 |
11 | Sydney | 澳大利亚 | 3487 |
12 | Paris | 法国 | 3175 |
13 | San Jose | 美国 | 2815 |
14 | Sao Paulo | 巴西 | 2753 |
15 | Cape Town | 南非 | 2692 |
16 | Montreal | 加拿大 | 2535 |
17 | Seattle | 美国 | 2534 |
18 | Hangzhou | 中国 | 2447 |
19 | Seoul | 韩国 | 2327 |
20 | Osaka | 日本 | 2184 |
5.3 美国地区城市分布 Top 10
排名 | 城市 (City) | 独立IP数 |
|---|---|---|
1 | Ashburn | 5808 |
2 | Portland | 5130 |
3 | Columbus | 3672 |
4 | San Jose | 2815 |
5 | Seattle | 2534 |
6 | Westlake Village | 1714 |
7 | Boardman | 855 |
8 | Florence | 776 |
9 | San Francisco | 753 |
10 | Boulder | 642 |

5.4 中国大陆地区城市分布 Top 10
香港、台湾的部署未在Top10城市表中体现,因已在国家/地区统计中已包含。
排名 | 城市 (City) | 所属 ( | 独立IP数 |
|---|---|---|---|
1 | Beijing | 中国 | 3906 |
2 | Hangzhou | 中国 | 2447 |
3 | Shanghai | 中国 | 1335 |
4 | Guangzhou | 中国 | 1296 |
5 | Shenzhen | 中国 | 768 |
6 | Chengdu | 中国 | 469 |
7 | Nanjing | 中国 | 329 |
8 | Chongqing | 中国 | 259 |
9 | Suzhou | 中国 | 257 |
10 | Wuhan | 中国 | 249 |

5.5 美中 Top 10 城市部署对比
为了更直观地比较中美两国 Ollama 在城市层面的部署情况,下表将两国 Top 10 城市的独立IP部署数量并列展示:
排名 | 美国城市 (Top 10) | 美国独立IP数 | 中国城市 (Top 10) | 中国独立IP数 | |
|---|---|---|---|---|---|
1 | Ashburn | 5808 | Beijing | 3906 | |
2 | Portland | 5130 | Hangzhou | 2447 | |
3 | Columbus | 3672 | Shanghai | 1335 | |
4 | San Jose | 2815 | Guangzhou | 1296 | |
5 | Seattle | 2534 | Shenzhen | 768 | |
6 | Westlake Village | 1714 | Chengdu | 469 | |
7 | Boardman | 855 | Nanjing | 329 | |
8 | Florence | 776 | Chongqing | 259 | |
9 | San Francisco | 753 | Suzhou | 257 | |
10 | Boulder | 642 | Wuhan | 249 |

简评:
头部城市体量:美国Top 3城市的Ollama部署数量(Ashburn, Portland, Columbus)均超过3000个独立IP。中国Top 1城市(北京)的部署数量超过3000个,Top 2城市(杭州)超过2000个。
科技与经济中心:两国上榜城市多为知名的科技创新中心或重要经济区域。
数据中心区域:美国的一些城市如Ashburn的上榜,也反映了Ollama实例可能大量部署在云服务器和数据中心内。
分布差异:整体来看,美国Top 10城市的IP总数远高于中国Top 10城市。但两国均呈现出少数几个核心城市占据了Ollama部署的绝大部分的特点。
这种城市级别的对比,进一步揭示了Ollama作为一种开发者工具,其推广和应用与区域性的技术生态和产业发展紧密相连。
6. 模型分析
6.1 AI 模型、参数与量化简述
Ollama 支持多种开源大型语言模型。这些模型通常通过以下特征进行区分:
6.1.1 常见模型家族
当前开源社区涌现了众多优秀的 LLM 家族,各有特点:
Llama 系列 (Meta AI): 如 Llama 2, Llama 3, Code Llama。以其强大的通用能力和广泛的社区支持著称,衍生出众多微调版本。我们数据中看到的
llama3.1,hermes3等通常基于 Llama 架构。Mistral 系列 (Mistral AI): 如 Mistral 7B, Mixtral 8x7B。以高效和高性能受到关注,特别是其 MoE (Mixture of Experts) 模型。
Gemma 系列 (Google): 如 Gemma 2B, Gemma 7B。Google 推出的开放权重模型,技术源自其更强大的 Gemini 模型。
Phi 系列 (Microsoft): 如 Phi-2, Phi-3。专注于小尺寸但能力出众的模型,强调 "SLMs (Small Language Models)"。
DeepSeek 系列 (DeepSeek AI): 如 DeepSeek Coder, DeepSeek LLM。在编码和通用任务上表现优异的中国AI模型。
Qwen 系列 (阿里巴巴通义千问): 如 Qwen1.5。阿里巴巴达摩院推出的系列模型,支持多种语言和任务。
其他还有许多优秀的模型,如 Yi (零一万物), Command R (Cohere) 等。
Ollama 通过其 Modelfile 机制,使得用户可以方便地使用这些基础模型或其微调版本。模型名称通常采用 family:size-variant-quantization 的格式,例如 llama3:8b-instruct-q4_K_M。
6.1.2 模型参数 (Parameter Size)
模型参数量(通常以 B - Billion,十亿;或 M - Million,百万为单位)是衡量模型规模和潜在能力的一个重要指标。常见的参数规模有:
小型模型: < 7B (例如 1.5B, 2B, 3B)。通常运行速度快,资源消耗低,适合特定任务或资源受限的环境。
中型模型: 7B, 8B, 13B。在能力和资源消耗之间取得了较好的平衡,是目前社区中最受欢迎的尺寸之一。
大型模型: 30B, 33B, 40B, 70B+。通常能力更强,但也需要更多的计算资源(RAM, VRAM)和更长的推理时间。
我们数据中的 parameter_size 字段(如 "8.0B", "7B", "134.52M")标示了这一点。
6.1.3 量化版本 (Quantization Level)
量化是一种缩减模型大小和加速推理的技术,它通过降低模型权重的数值精度来实现(例如从 16 位浮点数 FP16 降至 4 位整数 INT4)。
常见量化级别: Ollama 和 GGUF 格式(Llama.cpp 使用的格式)支持多种量化策略,如
Q2_K,Q3_K_S,Q3_K_M,Q3_K_L,Q4_0,Q4_K_M,Q5_K_M,Q6_K,Q8_0等。数字(如 2, 3, 4, 5, 6, 8)大致表示比特数。
K系列量化(如Q4_K_M)是 llama.cpp 中引入的改进量化方法,通常能在相同比特数下获得更好的性能。_S,_M,_L通常表示 K-quants 的不同变体,影响模型的不同部分。F16(FP16) 表示 16 位浮点数,通常被认为是未经量化的或基础量化版本。F32(FP32) 是全精度。
权衡: 量化程度越高(比特数越低),模型越小,运行越快,但通常会伴随一定的性能损失(模型表现变差)。用户需要根据自己的硬件和对模型质量的要求进行选择。
我们数据中的 quantization_level 字段(如 "Q4_K_M", "F16")标示了这一点。
6.2 Top 热门模型名称
下表展示了按独立IP部署数量排名的 Top 10 模型标签,包含其家族、参数规模和量化等级信息。
排名 | 模型名称 (model_name) | 独立IP部署数 | 总部署实例数 |
|---|---|---|---|
1 |
| 12659 | 24628 |
2 |
| 12572 | 24578 |
3 |
| 11163 | 22638 |
4 |
| 9868 | 21007 |
5 |
| 9845 | 20980 |
6 |
| 4058 | 5016 |
7 |
| 3124 | 3928 |
8 |
| 2856 | 3372 |
9 |
| 2714 | 3321 |
10 |
| 2668 | 3391 |

(注:独立IP部署数指至少部署了一个该模型标签的独立IP地址数量。总部署实例数指该模型标签在所有IP的 models 列表中出现的总次数。一个IP上可能通过不同方式或记录指向同一个模型标签多次,或者一个IP上同时运行了多个不同标签但属于同一基础模型的实例。)
初步观察 (热门模型名称):
带有
:latest标签的模型非常普遍,例如llama3:latest,deepseek-r1:latest,mistral:latest,qwen:latest。这表明许多用户倾向于直接拉取模型的最新版本。Llama 系列模型(如
llama3:latest,llama3:8b-text-q4_K_S,llama2:latest,llama3.1:8b)占据了多个席位,显示了其强大的受欢迎程度。中国的AI模型如
deepseek-r1:latest(DeepSeek 系列) 和qwen:latest(通义千问系列) 也表现抢眼,位列前茅。特定量化版本如
llama3:8b-text-q4_K_S也进入了前十,说明用户对特定性能/资源消耗平衡点的偏好。小型模型如
smollm2:135m和qwen2.5:1.5b也有相当的部署量,满足了对轻量级模型的需求。
6.3 Top 模型家族
模型家族( details.family 字段)代表了模型的基础架构或主要的技术谱系。以下是根据我们数据分析得到的部署数量较多的模型家族:
排名 | 模型家族 (family) | 独立IP部署数 (估算) | 总部署实例数 (估算) |
|---|---|---|---|
1 |
| ~20250 | ~103480 |
2 |
| ~17881 | ~61452 |
3 |
| ~1479 | ~1714 |
4 |
| ~1363 | ~2493 |
5 |
| ~1228 | ~2217 |
6 |
| ~943 | ~1455 |
7 |
| ~596 | ~750 |
8 |
| ~484 | ~761 |
9 |
| ~368 | ~732 |
10 |
| ~244 | ~680 |

(注:此处的具体数值基于之前成功查询的Top 50模型详情列表进行推算和汇总,可能与全局精确统计略有差异,但趋势具有代表性。)
初步观察 (热门模型家族):
llama家族占据绝对主导地位,这与 Llama 系列模型作为许多现代开源LLM的基础和其自身的广泛应用是一致的。其庞大的生态系统和众多的微调版本使其成为最受欢迎的选择。qwen2(通义千问Qwen2系列) 作为第二大家族,显示了其在中国乃至全球市场上的强大竞争力。nomic-bert和bert的出现值得关注。虽然它们通常不被视为典型的"大型语言模型"(对话型),而是更偏向于文本嵌入 (embedding) 或其他自然语言处理基础模型,但其较高的部署量表明 Ollama 也被广泛用于此类任务。Ollama 在执行某些操作(如生成嵌入向量)时会自动下载一个默认的嵌入模型(例如nomic-embed-text),这很可能是这些家族排名靠前的主要原因。Google 的
gemma系列(包括gemma3,gemma,gemma2)也显示出不错的采用率。deepseek2和phi3等其他知名模型家族也进入了前十。mllama可能代表了多种基于 Llama 的混合、修改或社区命名的模型集合。
6.4 Top 原始参数大小统计
模型参数大小(details.parameter_size 字段)是衡量模型规模的重要指标。由于原始数据中参数大小的表示方式多样(如 "8.0B", "7B", "134.52M"),我们直接按这些原始字符串进行统计,以下是部署数量较多的参数大小表示:
排名 | 参数大小 (原始字符串) | 独立IP部署数 (估算) | 总部署实例数 (估算) |
|---|---|---|---|
1 |
| ~14480 | ~52577 |
2 |
| ~14358 | ~28105 |
3 |
| ~11233 | ~22907 |
4 |
| ~9895 | ~21058 |
5 |
| ~4943 | ~11738 |
6 |
| ~4062 | ~5266 |
7 |
| ~2759 | ~3596 |
8 |
| ~2477 | ~3311 |
9 |
| ~2034 | ~2476 |
10 |
| ~1553 | ~2244 |
11 |
| ~1477 | ~1708 |
12 |
| ~1421 | ~2000 |
13 |
| ~1254 | ~2840 |
14 |
| ~1123 | ~2091 |
15 |
| ~943 | ~1194 |
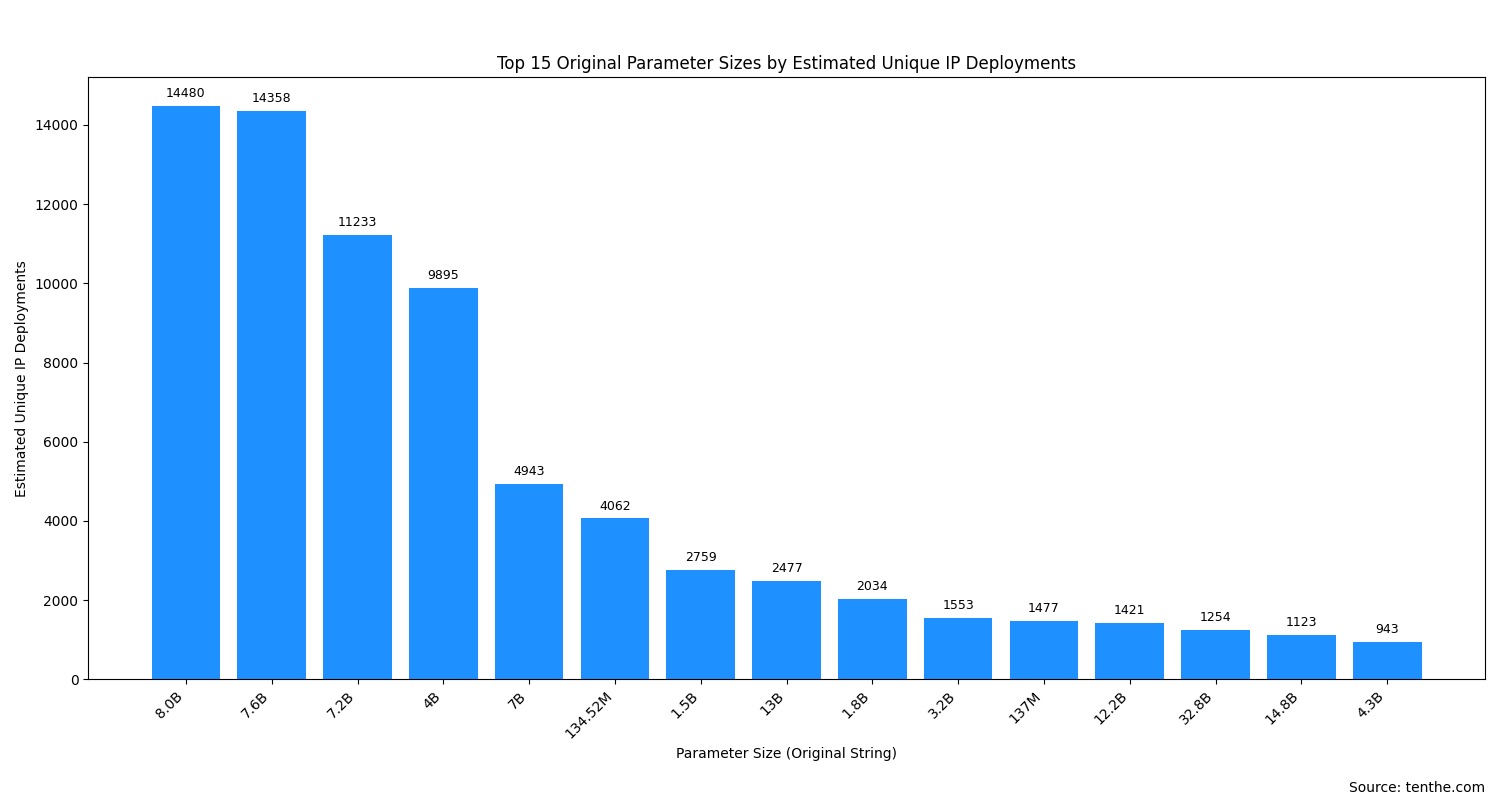
(注:数值基于之前查询的Top 50模型详情列表中的参数信息汇总推算。)
初步观察 (热门参数大小):
7B 到 8B 规模的模型是绝对主流: "8.0B", "7.6B", "7.2B", "7B" 这几个档位占据了部署数量的绝大部分。这通常对应于社区中非常流行的模型,如 Llama 2/3 7B/8B 系列、Mistral 7B 及其各种微调版本。它们在性能和资源消耗之间取得了良好的平衡。
4B 规模的模型也占有重要地位: "4B" 的高部署量值得注意。
百万参数级别 (M) 的轻量级模型广泛存在: "134.52M" 和 "137M" 的高排名,很可能与嵌入模型(如
nomic-embed-text)或非常小的专用模型(如smollm系列)的普及有关。这些模型体积小、速度快,适合资源受限或对延迟要求高的场景。1B-4B 区间的小型模型有稳定需求: "1.5B", "1.8B", "3.2B", "4.3B" 等参数规模的模型也受到一部分用户的青睐。
10B以上的大型模型: 如 "13B", "12.2B", "32.8B", "14.8B" 等虽然独立IP部署数不如7-8B级别,但仍有可观的部署量,表明社区对更强能力模型的需求,尽管它们对硬件要求更高。
6.5 Top 量化级别统计
模型量化级别(details.quantization_level 字段)反映了模型为减小体积、加速推理所采用的权重精度。以下是部署数量较多的量化级别:
排名 | 量化级别 (原始字符串) | 独立IP部署数 (估算) | 总部署实例数 (估算) |
|---|---|---|---|
1 |
| ~20966 | ~53688 |
2 |
| ~18385 | ~88653 |
3 |
| ~9860 | ~21028 |
4 |
| ~5793 | ~9837 |
5 |
| ~596 | ~1574 |
6 |
| ~266 | ~1318 |
7 |
| ~97 | ~283 |
8 |
| ~85 | ~100 |
9 |
| ~60 | ~178 |
10 |
| ~54 | ~140 |

(注:数值基于之前查询的Top 50模型详情列表中的量化信息汇总推算。)
初步观察 (热门量化级别):
4-bit 量化是主导方案:
Q4_K_M,Q4_0, 和Q4_K_S这三种 4-bit 量化级别占据了排行榜的绝对前列。这清晰地表明,社区普遍采用 4-bit 量化作为在模型性能、推理速度和资源占用(特别是显存)之间取得最佳平衡点的首选方案。F16(16-bit 浮点数) 仍有重要一席: 作为未进行深度量化(或仅基础量化)的版本,F16的高部署量说明有相当一部分用户为了追求模型的最高保真度,或者拥有足够的硬件资源而选择它。Q8_0(8-bit 量化) 作为补充: 提供了介于 4-bit 和F16之间的选项。unknown值的出现: 表明部分模型元数据中量化级别信息缺失或不规范。
6.6 按模型参数规模划分的算力分布:中美对比
为了更深入地理解不同规模模型在主要国家的部署情况,我们对美国和中国的Ollama实例所部署模型的参数规模进行了分类统计。参数规模通常被视为衡量模型复杂度和潜在AI算力需求的一个重要指标。
参数规模分类标准:
小型 (Small): < 10亿参数 (< 1B)
中型 (Medium): 10亿 至 < 100亿参数 (1B to < 10B)
大型 (Large): 100亿 至 < 500亿参数 (10B to < 50B)
超大型 (Extra Large): >= 500亿参数 (>= 50B)
下表展示了在美国和中国,部署不同参数规模模型的独立IP数量:
国家 | 参数规模分类 | 独立IP数 |
|---|---|---|
中国 | 小型 (<1B) | 3313 |
中国 | 中型 (1B 至 <10B) | 4481 |
中国 | 大型 (10B 至 <50B) | 1548 |
中国 | 超大型 (>=50B) | 280 |
美国 | 小型 (<1B) | 1368 |
美国 | 中型 (1B 至 <10B) | 6495 |
美国 | 大型 (10B 至 <50B) | 1301 |
美国 | 超大型 (>=50B) | 58 |
--China-vs-USA.jpeg)
数据洞察与分析:
中型模型为主流,但侧重不同:
美国:中型模型 (1B-10B) 的部署数量在美国占据绝对主导地位 (6495个独立IP)。
中国:中型模型 (4481个独立IP) 同样是中国部署最多的类型,但小型模型 (<1B) 在中国的部署数量 (3313个独立IP) 非常可观。
小型模型的显著差异:中国在小型模型上的大量部署可能反映了在边缘计算、移动端AI应用等场景的偏好。
大型与超大型模型的部署:中国在大型和超大型模型的探索上表现出更高的活跃度(尽管基数较小)。
总体算力投入推测:美国在中型模型上的基数显示了实用型AI应用的普及。中国在小型模型有优势,并在大模型探索上积极。
对全球趋势的启示:中型模型可能在全球受欢迎。不同地区根据其生态和资源条件在模型采用上可能存在差异。
通过对中美两国模型参数规模的细分,我们可以看到两国在Ollama应用上的不同侧重点和发展潜力。
7. 网络洞察
7.1 端口使用情况
11434(默认端口):绝大多数 (30,722个独立IP) Ollama 实例运行在默认端口11434上。其他常见端口:如
80(1,619个独立IP),8080(1,571个独立IP),443(1,339个独立IP) 等也有使用,这可能表明部分实例部署在反向代理之后,或用户自定义了端口。
7.2 协议使用情况
HTTP: 约 65,506 个独立IP上的实例通过 HTTP 协议提供服务。
HTTPS: 约 43,765 个独立IP上的实例通过 HTTPS 协议提供服务。
多数实例仍通过未加密的 HTTP 协议暴露,这可能带来一定的安全风险。 (请注意:一个IP可能同时支持HTTP和HTTPS,因此这里的IP计数加总可能大于总独立IP数)
7.3 主要托管服务商 (AS Organization)
Ollama 实例的托管呈现高度集中于云服务提供商的特点。
排名 | AS Organization | 独立IP数 | 主要关联服务商 |
|---|---|---|---|
1 | AMAZON-02 | 53658 | AWS |
2 | AMAZON-AES | 5539 | AWS |
3 | Chinanet | 4964 | 中国电信 |
4 | Hangzhou Alibaba Advertising Co.,Ltd. | 2647 | 阿里云 |
5 | HENGTONG-IDC-LLC | 2391 | Hosting Provider |
6 | Shenzhen Tencent Computer Systems Company Limited | 1682 | 腾讯云 |
7 | CHINA UNICOM China169 Backbone | 1606 | 中国联通 |
8 | Hetzner Online GmbH | 972 | Hetzner |
9 | China Unicom Beijing Province Network | 746 | 中国联通 (北京) |
10 | LEASEWEB-USA-LAX | 735 | Leaseweb |

AWS (AMAZON-02, AMAZON-AES) 占据了最大的份额,其次是中国的主要电信运营商和云服务商(如阿里云、腾讯云)。Hetzner 和 Leaseweb 等其他主机提供商也有显著份额。
8. 安全与其他观察点
版本信息:因为一些安全原因,我们并未对Ollama的版本统计信息列出。
HTTP暴露风险:如前所述,大量Ollama实例通过HTTP暴露,未进行TLS加密,这可能使得通信内容(例如与模型的交互)容易被窃听或篡改。建议用户配置反向代理并启用HTTPS。
API可访问性:本报告的数据基于可公开访问
/api/tags接口的Ollama实例。实际部署量可能更高,但部分实例可能部署在私有网络或通过防火墙限制了外部访问。
9. 总结与简评
本报告通过对全球范围内 99,412 个可公开访问其 /api/tags 接口的 Ollama 实例数据进行分析,得到以下主要结论与观察:
1. 全球部署概况与地理分布:
Ollama 作为一款便捷的本地大模型运行工具,在全球范围内得到了广泛部署。本次分析识别的可公开访问IP数为 99,412。
地理集中度高: 美国和中国是 Ollama 部署最为集中的两个国家/地区,合计占据了可访问实例总数的相当一部分(美国 29,195,中国 16,464)。日本、德国、英国、印度、新加坡等国家也有显著的部署量。
城市热点: 在美国,Ashburn, Portland, Columbus 等城市部署量领先;在中国,北京、杭州、上海、广州等科技发达城市是主要部署地。这通常与科技公司、数据中心和开发者社区的聚集有关。
2. AI 模型部署趋势:
热门模型标签:
llama3:latest,deepseek-r1:latest,mistral:latest,qwen:latest等通用最新标签最受欢迎。特定优化版本如llama3:8b-text-q4_K_S也因其良好的平衡性而受到青睐。主导模型家族:
llama家族以绝对优势领先,其次是qwen2。嵌入模型家族如nomic-bert和bert的高排名值得注意,可能与Ollama的默认行为有关。参数规模偏好: 7B-8B 参数规模的模型是当前部署的主流。百万参数级别的轻量级模型和 10B 以上的大型模型也各有市场。中美对比显示,美国在中型模型上部署更多,而中国在小型和超大型模型的探索上表现更活跃。
量化级别选择: 4-bit 量化(特别是
Q4_K_M和Q4_0)是压倒性的选择。F16作为保真度较高的选项也占有重要地位。元数据复杂性: 模型元数据的分析(例如对模型家族字段的解读)有时会揭示其记录与模型名称或普遍认知之间的复杂性,突显了开源生态中元数据管理的多样性。
3. 技术基础设施:
托管环境: 大量 Ollama 实例托管在如 AWS、阿里云、腾讯云等大型云服务提供商以及各国主要电信运营商的网络中。
服务端口: Ollama 的默认端口
11434是最常用的端口,但也有不少实例通过标准Web端口暴露。
4. 客观评价:
Ollama 的普及性: 数据清晰地显示了 Ollama 在全球开发者和AI爱好者中的高采用率。
开源生态的活力: 热门模型的多样性以及各种参数和量化版本的广泛使用,反映了开源AI模型生态系统的蓬勃发展。
用户偏好的平衡: 用户在选择模型时,倾向于在模型能力、运行效率和硬件成本之间寻找平衡点。
安全与开放性: 大量实例允许公开访问其模型列表,这在方便社区的同时也可能带来安全风险。
5. 未来展望:
随着更多高效、小型化模型的出现,以及量化技术的进一步发展,Ollama 的部署门槛有望持续降低。
模型元数据的规范化和社区共享模型的标准化对于提升生态系统的透明度和易用性至关重要。
总而言之,Ollama 正在成为连接前沿大型语言模型与广大开发者、研究人员乃至普通用户的重要桥梁。本次数据分析为我们理解其当前全球部署态势和用户偏好提供了有价值的参考。
评论
comments.comments (0)
Please login first
Sign in